摘要
本篇是 MIT6.S081 的实验课程的 lab1 实验报告。实验内容是在一个类 unix 操作系统 xv6 上实现各种功能。lab1 内容较为简单,主要是通过系统调用实现一些工具程序。
目录结构
可以看到源代码主要分为两个目录 user/, kernal/,分别对应用户程序和内核程序。在 user/user.h 中,声明了 xv6 支持的系统调用和一些工具函数,工具函数的实现在 user/ulib.c 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| struct stat;
struct rtcdate;
int fork(void);
int exit(int) __attribute__((noreturn));
int wait(int*);
int stat(const char*, struct stat*);
char* strcpy(char*, const char*);
void *memmove(void*, const void*, int);
|
此外,user/ 目录下也保存了用户态的应用程序,以 echo.c 为例,通过 main 完成命令行传参,使用 write 系统调用完成写入标准输出流,调用 exit 显式结束执行。程序需要加入 makefile 中的 UPROGS,才会被编译加载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| #include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[])
{
int i;
for(i = 1; i < argc; i++){
write(1, argv[i], strlen(argv[i]));
if(i + 1 < argc){
write(1, " ", 1);
} else {
write(1, "\n", 1);
}
}
exit(0);
}
|
kernel 目录下,syscall.h, syscall.c 声明了系统调用号及映射关系,系统调用的实现在 sysproc.c, sysfile.c 等文件中。在本次 lab 中只需要编写用户态程序。
Exercises
sleep
比较简单,调用 sleep 系统调用,实现用户程序,代码如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include "kernel/types.h"
#include "user/user.h"
int main(int argc, char *argv[])
{
int ticks;
if (argc <= 1)
{
fprintf(2, "usage: sleep n(ticks)");
exit(0);
}
ticks = atoi(argv[1]);
sleep(ticks);
exit(0);
}
|
pingpong
通过一对管道,实现父子进程的通信。
背景知识
在 linux 下,IO 资源均抽象为文件描述符(file description,fd),本质上就是一个整数,每个进程有一个独立的 fd 映射表,用于把 fd 映射为 IO 资源。标准输入 / 输出 / 异常分别映射到 0,1,2。在增加 IO 资源时,会分配最小可用的 fd。xv6 也使用了这种思想,因此可以通过关闭 fd,重新分配 fd 比较简单地实现 IO 重定向功能。参见实验指导书中的例子
xv6 中的 pipe 调用,用于初始化一对 fd 作为管道,分别用于读写。
解决方法
pipe 只能用于单向通信,为达到双向通信,需要创建一对 pipe,并关闭无用的写管道,避免 read 卡死。另外,为了避免交叉输出的混乱,建议在父进程中 wait 子进程结束再输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| #include "kernel/types.h"
#include "user/user.h"
int main(int argc, char *argv[])
{
int pid = fork();
int parent[2];
int child[2];
pipe(parent);
pipe(child);
if (pid == 0)
{
close(child[1]);
read(child[0], 0, 1);
fprintf(1, "%d: received ping\n", getpid());
write(parent[1], 0, 1);
}
else
{
close(parent[1]);
write(child[1], 0, 1);
read(parent[0], 0, 1);
wait(0);
fprintf(1, "%d: received pong\n", getpid());
}
exit(0);
}
|
primes
实现一个并行的素数筛。图示如下:
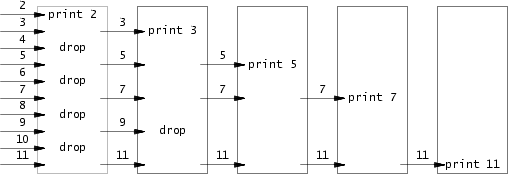
可以看到,其思想是一个流水线一样的操作。每个数从最左侧输入,在每个模块里,通过下面的伪代码,从左侧读入数,判断是否能被当前模块的素数整除,若不能再送到右边的模块。
1
2
3
4
5
6
| p = get a number from left neighbor
print p
loop:
n = get a number from left neighbor
if (p does not divide n)
send n to right neighbor
|
需要思考的一个点就是模块是什么时候创建的。实验要求我们只能在必要的时候创建模块。思考这个过程可以发现,如果一个数到达了流水线的边界还没有被筛掉,就意味着它是一个素数,就需要在流水线末尾创建一个模块用于筛去它的倍数。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| #include "kernel/types.h"
#include "user/user.h"
int p[40][2];
void process(int idx, int prime)
{
fprintf(1, "prime %d\n", prime);
int num;
while (read(p[idx][0], &num, 4))
{
if (num % prime != 0)
{
if (p[idx + 1][0] == 0)
{
pipe(p[idx + 1]);
if (fork() == 0)
{
close(p[idx + 1][1]);
process(idx + 1, num);
}
else
{
close(p[idx + 1][0]);
}
}
else
{
write(p[idx + 1][1], &num, 4);
}
}
}
close(p[idx][0]);
if (p[idx + 1][1])
{
close(p[idx + 1][1]);
}
wait(0);
exit(0);
}
int main(int argc, char *argv[])
{
int nums[34];
for (int i = 0; i < 34; i++)
{
nums[i] = i + 2;
}
pipe(p[0]);
if (fork() == 0)
{
close(p[0][1]);
process(0, 2);
}
else
{
close(p[0][0]);
write(p[0][1], nums, sizeof(nums));
close(p[0][1]);
wait(0);
}
exit(0);
}
|
find
实现类似 linux find 的功能。也比较简单,需要注意的是当文件夹匹配查找名的时候,就不用递归向下了。从 ls.c 中可以借鉴读取文件类型和遍历文件夹的逻辑。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| #include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
char buf[1024];
int idx;
void find(char *path, char *filename)
{
if (strcmp(path, filename) == 0)
{
printf("%s%s\n", buf, path);
return;
}
int ori = idx;
int fd;
struct dirent de;
struct stat st;
char *p = buf + idx;
int len = strlen(path);
memcpy(p, path, len + 1);
idx += len;
if ((fd = open(buf, 0)) < 0)
{
fprintf(2, "find: cannot open %s\n", buf);
return;
}
if (fstat(fd, &st) < 0)
{
fprintf(2, "find: cannot stat %s\n", path);
close(fd);
return;
}
switch (st.type)
{
case T_FILE:
break;
case T_DIR:
if (idx + 1 + DIRSIZ + 1 > sizeof buf)
{
printf("find: path too long\n");
break;
}
buf[idx++] = '/';
buf[idx] = 0;
char name[15];
while (read(fd, &de, sizeof(de)) == sizeof(de))
{
if (de.inum == 0)
continue;
memcpy(name, de.name, DIRSIZ);
name[DIRSIZ] = 0;
if (strcmp(name, ".") == 0 || strcmp(name, "..") == 0)
{
continue;
}
find(name, filename);
}
break;
}
close(fd);
idx = ori;
buf[idx] = 0;
}
int main(int argc, char *argv[])
{
if (argc < 3)
{
fprintf(2, "usage: find {path} {filename}");
exit(0);
}
find(argv[1], argv[2]);
exit(0);
}
|
xargs
实现类似 linux xargs 的功能。从标准输入读取每一行,作为参数加在命令的后面。最简单的做法就是按实验提示,每次读入一个字符,如果是换行就处理这一行,否则继续读。不过每次读一个字符会有很大的 IO 开销,实际应用中肯定是不能这么写的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| #include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
#include "kernel/param.h"
char buf[1024];
int main(int argc, char *argv[])
{
int idx = 0;
if (argc <= 1)
{
fprintf(2, "usage: xargs commands...");
exit(0);
}
char *params[MAXARG];
for (int i = 1; i < argc; i++)
{
params[i - 1] = argv[i];
}
params[argc] = 0;
while (read(0, buf + idx, 1))
{
if (buf[idx] != '\n')
{
idx++;
continue;
}
buf[idx] = 0;
if (fork() == 0)
{
params[argc - 1] = buf;
exec(params[0], params);
fprintf(2, "command failed:");
for (int i = 0; i < argc + 1; i++)
{
fprintf(2, "%s ", params[i]);
}
fprintf(2, "\n");
exit(1);
}
else
{
wait(0);
idx = 0;
}
}
exit(0);
}
|
参考
我个人使用的是 2021 年秋季版本。课程官网为 6.S081 / Fall 2021 (mit.edu)。